
By Abhinaya Shetty, Bharath Mummadisetty
At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Many metrics in Netflix’s financial reports are powered and reconciled with efforts from our team! Given our role on this critical path, accuracy is paramount. In this context, managing the data, especially when it arrives late, can present a substantial challenge!
In this three-part blog post series, we introduce you to Psyberg, our incremental data processing framework designed to tackle such challenges! We’ll discuss batch data processing, the limitations we faced, and how Psyberg emerged as a solution. Furthermore, we’ll delve into the inner workings of Psyberg, its unique features, and how it integrates into our data pipelining workflows. By the end of this series, we hope you will gain an understanding of how Psyberg transformed our data processing, making our pipelines more efficient, accurate, and timely. Let’s dive in!
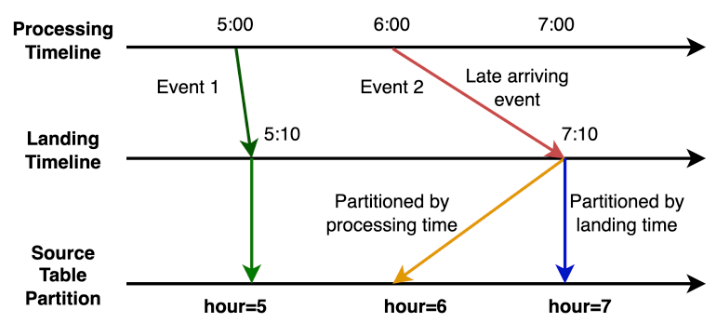
Our teams’ data processing model mainly comprises batch pipelines, which run at different intervals ranging from hourly to multiple times a day (also known as intraday) and even daily. We expect complete and accurate data at the end of each run. To meet such expectations, we generally run our pipelines with a lag of a few hours to leave room for late-arriving data.
Late-arriving data is essentially delayed data due to system retries, network delays, batch processing schedules, system outages, delayed upstream workflows, or reconciliation in source systems.
You could think of our data as a puzzle. With each new piece of data, we must fit it into the larger picture and ensure it’s accurate and complete. Thus, we must reprocess the missed data to ensure data completeness and accuracy.

Based on the structure of our upstream systems, we’ve classified late-arriving data into two categories, each named after the timestamps of the updated partition:


